The Challenge of Heart Failure
Heart failure is a serious medical condition in which the heart is unable to pump enough blood to meet the body’s needs. As a leading cause of death worldwide, it poses a significant public health challenge. The key to saving lives? Early detection and accurate prediction of heart failure risk for timely intervention and effective management.
Image: Medical illustration showing a healthy heart vs. a heart with heart failure, highlighting the reduced pumping capacity
In this post, I’ll walk you through building a machine learning model that predicts the likelihood of heart failure in patients based on clinical and demographic features. By analyzing relevant medical data, we can identify individuals at higher risk and enable healthcare professionals to provide personalized treatment plans.
Understanding Heart Failure and Its Risk Factors
Heart failure occurs when the heart becomes weakened or damaged, resulting in a reduced ability to pump blood effectively. Common causes include:
- Coronary artery disease
- Hypertension
- Heart valve disorders
- Cardiomyopathy
The good news? Identifying risk factors and early signs of heart failure can significantly improve patient outcomes and reduce mortality rates. With electronic health records and advancements in machine learning, we now have powerful tools to develop predictive models that learn patterns indicative of heart failure risk.
The Dataset: What We’re Working With
Our dataset contains clinical and demographic features of patients, along with a binary target variable indicating whether they experienced a heart failure event. Here are the key features:
- age: Patient’s age
- creatinine_phosphokinase: Level of CPK enzyme in the blood
- ejection_fraction: Percentage of blood leaving the heart at each contraction
- platelets: Platelet count in the blood
- serum_creatinine: Level of serum creatinine in the blood
- serum_sodium: Level of serum sodium in the blood
- time: Follow-up period in days
- DEATH_EVENT: Target variable (0: No heart failure event, 1: Heart failure event)
Each row represents a unique patient from a medical study, and our goal is to classify patients as high-risk or low-risk for heart failure based on these medical characteristics.
Approach to Building the Predictive Models:
Step 1: Data Exploration and Preprocessing
We start by importing necessary libraries (NumPy, Pandas, Matplotlib, Seaborn, Scikit-learn, and Keras) and loading our dataset. Initial exploration includes:
- Examining the first few rows with
head() - Checking data types and missing values with
info() - Visualizing the target variable distribution
- Calculating descriptive statistics
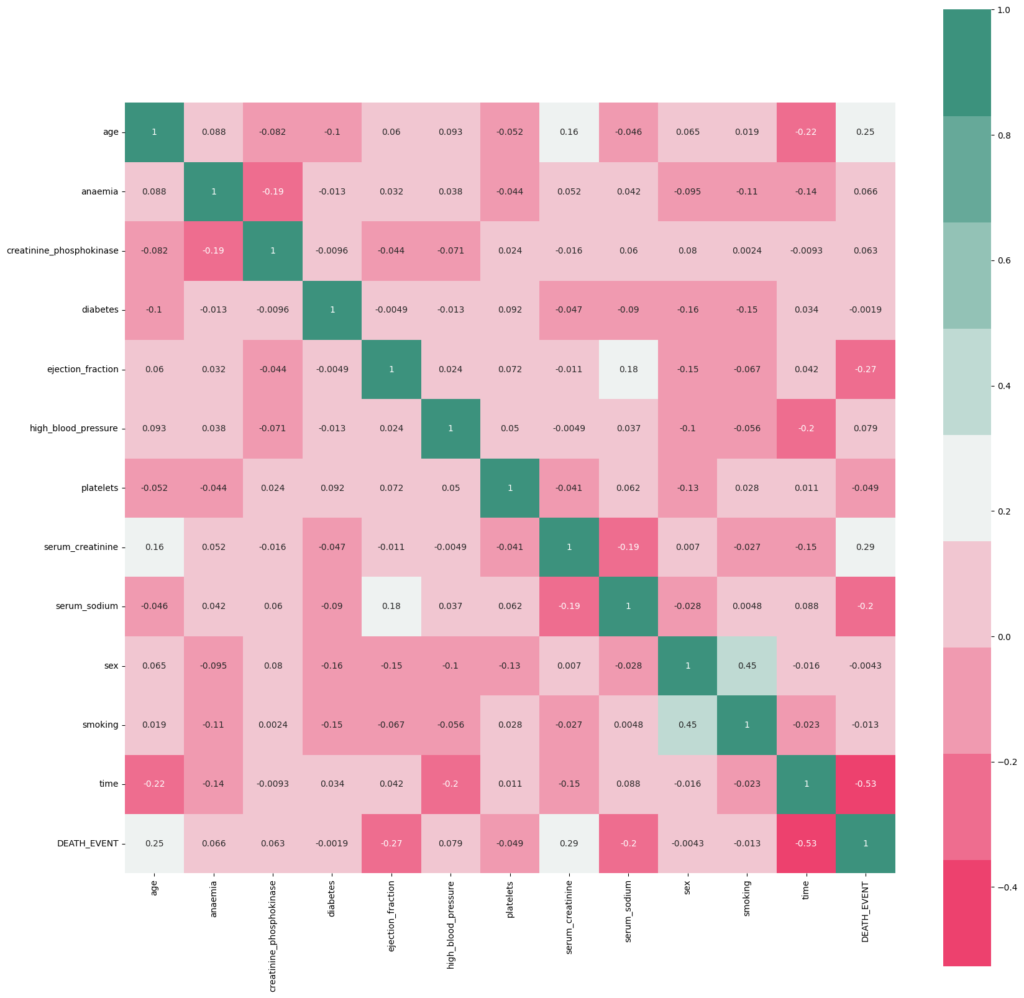
- Creating correlation matrices to understand feature relationships
Before modeling, we standardize numerical features using StandardScaler to ensure all features are on the same scale—a crucial step for optimal model performance.
Step 2: Train-Test Split
We divide the dataset into training and testing sets, allowing us to train our models on one portion of the data and evaluate their performance on unseen data. This ensures our models can generalize well to new patients.
Step 3: Model 1 – Support Vector Machine (SVM)
Our first approach uses a Support Vector Machine, a powerful classification algorithm. The process:
- Initialize the SVM model using Scikit-learn’s SVC class
- Fit the model on training data
- Make predictions on test data
- Evaluate performance using accuracy, precision, recall, F1-score, and confusion matrix
Step 4: Model 2 – Neural Network (Keras)
For our second model, we build a neural network capable of capturing complex patterns:
- Create a Sequential model with multiple dense layers
- Use ReLU activation functions
- Implement dropout layers to prevent overfitting
- Compile with Adam optimizer and binary cross-entropy loss
- Train with early stopping to maintain generalization
- Evaluate on test data and visualize training/validation metrics
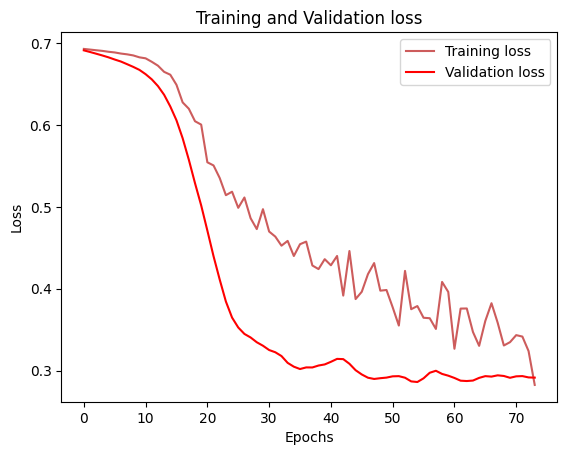
Fig: Side-by-side comparison charts showing training/validation loss and accuracy curves for the neural network model over epochs
Model Comparison and Results
After training both models, we compare their performance using various evaluation metrics and visualizations. The confusion matrices provide clear visual representations of how well each model performs in predicting heart failure outcomes.
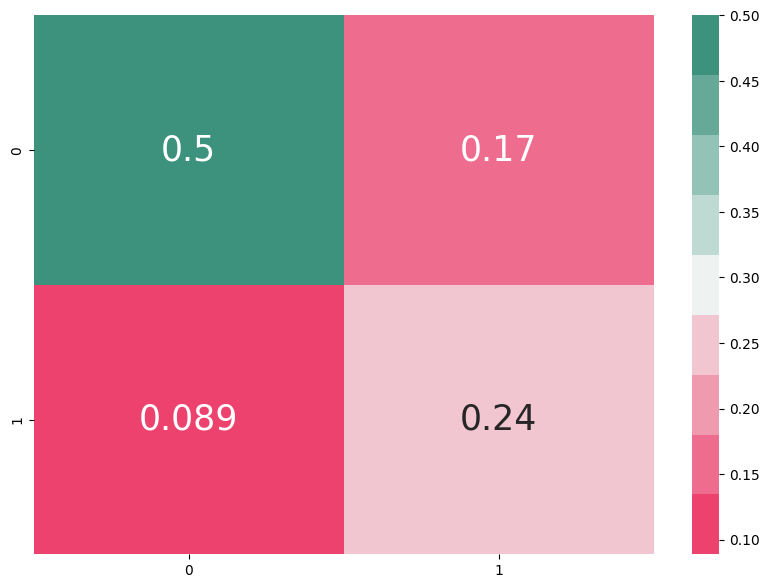
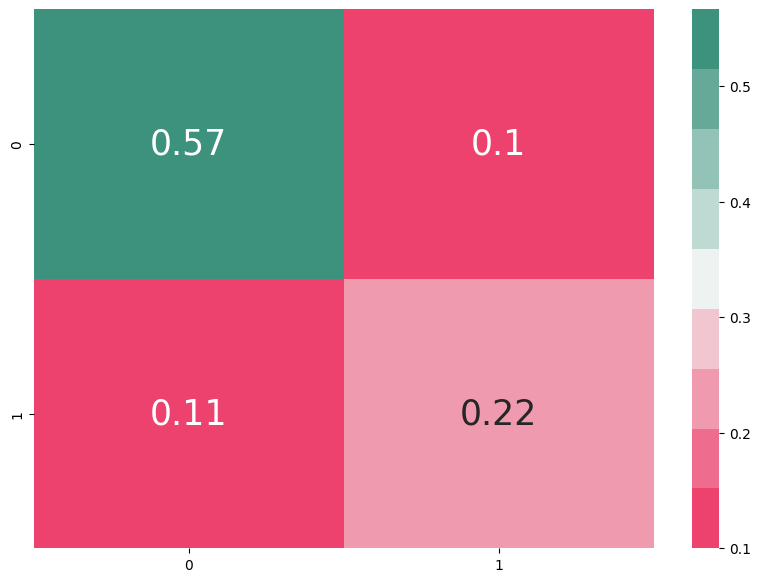
Fig: Confusion matrix for ANN (left) vs SVM (right)
By analyzing metrics like precision, recall, and F1-score, we can determine which model is best suited for heart failure prediction in clinical settings.
Conclusion: The Impact of Predictive Modeling
Our machine learning approach demonstrates the powerful potential of data-driven healthcare. Early heart failure prediction can:
- Enable timely medical intervention
- Support personalized treatment planning
- Improve patient outcomes and reduce mortality rates
- Optimize healthcare resource allocation
The best-performing model from our comparison offers healthcare professionals a valuable tool for identifying at-risk patients before symptoms become severe.
Future Directions
To further improve predictive accuracy and clinical utility, consider:
- Enhanced Features: Incorporating additional clinical markers and patient history
- Advanced Algorithms: Exploring ensemble methods, gradient boosting, or more sophisticated deep learning architectures
- Larger Datasets: Using more extensive medical datasets or longitudinal patient records to increase model robustness
- Clinical Validation: Testing models in real-world clinical settings with diverse patient populations
- Interpretability: Developing explainable AI techniques to help clinicians understand model predictions
Machine learning in healthcare is not just about building accurate models, it’s about saving lives through early detection and intervention. As we continue to refine these approaches, we move closer to a future where heart failure can be predicted and prevented before it becomes life-threatening.
Have you worked on healthcare prediction models? What challenges did you encounter? Share your experiences in the comments below!